Scrapy so với Selenium: Cái nào tốt nhất cho Dự án Ghi dữ liệu từ Web của bạn?

Rajinder Singh
Deep Learning Researcher

TL;DR
Scrapy và Selenium là hai công cụ phổ biến để khai thác web, mỗi công cụ phù hợp với các trường hợp sử dụng khác nhau. Scrapy là một khung Python nhanh, nhẹ và có thể mở rộng, lý tưởng cho việc khai thác web quy mô lớn trên các trang web tĩnh. Trong khi đó, Selenium tự động hóa trình duyệt thực tế và xuất sắc trong việc khai thác các trang web động, có nhiều JavaScript và yêu cầu tương tác người dùng. Lựa chọn đúng đắn phụ thuộc vào độ phức tạp của dự án, yêu cầu hiệu suất và nhu cầu tương tác, và cả hai công cụ này có thể gặp phải các thách thức CAPTCHA có thể được giải quyết bằng dịch vụ như CapSolver.
Giới thiệu
Khai thác web là một kỹ thuật quan trọng để thu thập dữ liệu từ internet, và ngày càng trở nên phổ biến trong số các nhà phát triển, nhà nghiên cứu và doanh nghiệp. Hai công cụ được sử dụng phổ biến nhất để khai thác web là Scrapy và Selenium. Mỗi công cụ đều có những ưu điểm và nhược điểm riêng, phù hợp với các loại dự án khác nhau. Trong bài viết này, chúng ta sẽ so sánh Scrapy và Selenium để giúp bạn xác định công cụ nào phù hợp nhất với nhu cầu khai thác web của mình.
Scrapy là gì
Scrapy là một khung khai thác web mạnh mẽ và nhanh chóng được viết bằng Python. Nó được thiết kế để trích xuất dữ liệu có cấu trúc từ các trang web. Scrapy rất hiệu quả, có thể mở rộng và tùy chỉnh, làm cho nó trở thành lựa chọn tuyệt vời cho các dự án khai thác web quy mô lớn.
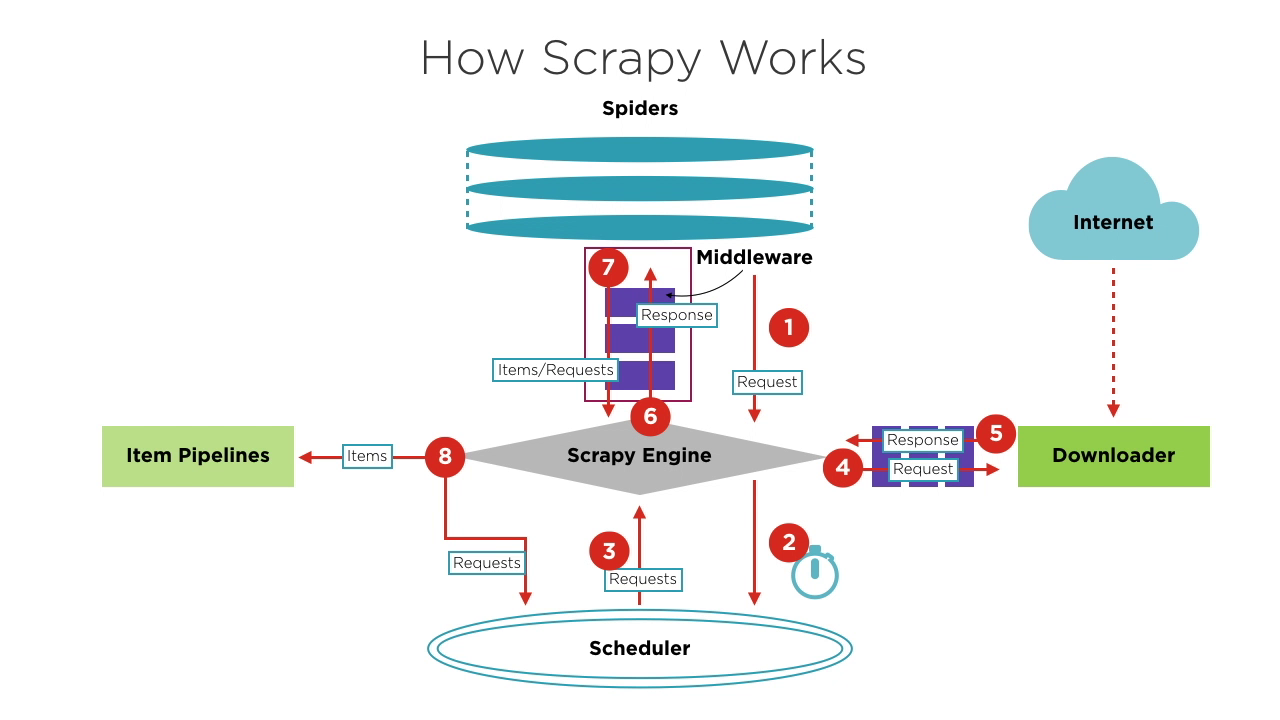
Các thành phần của Scrapy
- Động cơ Scrapy: Lõi của khung, quản lý luồng dữ liệu và sự kiện trong hệ thống. Nó giống như bộ não, xử lý chuyển tiếp dữ liệu và xử lý logic.
- Scheduler: Nhận các yêu cầu từ động cơ, hàng đợi chúng và gửi lại cho động cơ để trình tải xuống thực hiện. Nó duy trì logic lập lịch, như FIFO (First In First Out), LIFO (Last In First Out) và hàng đợi ưu tiên.
- Spiders: Xác định logic khai thác và phân tích trang. Mỗi spider chịu trách nhiệm xử lý các phản hồi, tạo ra các mục và các yêu cầu mới để gửi cho động cơ.
- Downloader: Xử lý việc gửi yêu cầu đến máy chủ và nhận phản hồi, sau đó gửi lại cho động cơ.
- Item Pipelines: Xử lý các mục được trích xuất bởi spiders, thực hiện các nhiệm vụ như làm sạch dữ liệu, kiểm tra tính hợp lệ và lưu trữ.
- Middlewares:
- Downloader Middlewares: Nằm giữa động cơ và trình tải xuống, xử lý yêu cầu và phản hồi.
- Spider Middlewares: Nằm giữa động cơ và spiders, xử lý các mục, yêu cầu và phản hồi.
Vướng phải sự cố lặp đi lặp lại trong việc giải quyết CAPTCHA khó chịu? Khám phá công nghệ giải CAPTCHA tự động liền mạch với CapSolver!
Tăng ngân sách tự động hóa của bạn ngay lập tức!
Sử dụng mã khuyến mãi CAPN khi nạp tiền vào tài khoản CapSolver để nhận thêm 5% khuyến mãi cho mỗi lần nạp — không giới hạn.
Nhận ngay tại Bảng điều khiển CapSolver của bạn
.
Quy trình cơ bản của dự án Scrapy
-
Khi bắt đầu một dự án khai thác, Động cơ tìm Spider xử lý trang web mục tiêu dựa trên trang web cần khai thác. Spider tạo ra một hoặc nhiều yêu cầu ban đầu tương ứng với các trang cần khai thác và gửi chúng cho Động cơ.
-
Động cơ nhận các yêu cầu này từ Spider và sau đó chuyển chúng cho Scheduler để chờ lập lịch.
-
Động cơ yêu cầu Scheduler về yêu cầu tiếp theo cần xử lý. Tại thời điểm này, Scheduler chọn một yêu cầu phù hợp dựa trên logic lập lịch của nó và gửi lại cho Động cơ.
-
Động cơ chuyển yêu cầu từ Scheduler đến Downloader để thực hiện tải xuống. Quá trình gửi yêu cầu đến Downloader đi qua xử lý của nhiều Downloader Middlewares được định nghĩa trước.
-
Downloader gửi yêu cầu đến máy chủ mục tiêu, nhận phản hồi tương ứng và sau đó trả lại cho Động cơ. Quá trình trả lại phản hồi cho Động cơ cũng đi qua xử lý của nhiều Downloader Middlewares được định nghĩa trước.
-
Phản hồi nhận được bởi Động cơ từ Downloader chứa nội dung của trang web mục tiêu. Động cơ sẽ gửi phản hồi này đến Spider tương ứng để xử lý. Quá trình gửi phản hồi đến Spider đi qua xử lý của Spider Middlewares được định nghĩa trước.
-
Spider xử lý phản hồi, phân tích nội dung của nó. Tại thời điểm này, Spider sẽ tạo ra một hoặc nhiều mục kết quả khai thác hoặc một hoặc nhiều yêu cầu tương ứng với các trang mục tiêu tiếp theo cần khai thác. Sau đó, nó gửi các mục hoặc yêu cầu này lại cho Động cơ để xử lý. Quá trình gửi các mục hoặc yêu cầu cho Động cơ đi qua xử lý của Spider Middlewares được định nghĩa trước.
-
Động cơ chuyển một hoặc nhiều mục được gửi lại bởi Spider đến Item Pipelines được định nghĩa trước để thực hiện các hoạt động xử lý hoặc lưu trữ dữ liệu. Nó cũng chuyển một hoặc nhiều yêu cầu được gửi lại bởi Spider đến Scheduler để chờ lập lịch tiếp theo.
Các bước 2 đến 8 được lặp lại cho đến khi không còn yêu cầu nào trong Scheduler. Khi đó, Động cơ sẽ đóng Spider, và toàn bộ quá trình khai thác kết thúc.
Tổng quan, mỗi thành phần chỉ tập trung vào một chức năng, độ耦 hợp giữa các thành phần rất thấp, và rất dễ mở rộng. Động cơ sau đó kết hợp các thành phần khác nhau, cho phép mỗi thành phần thực hiện nhiệm vụ của mình, hợp tác với nhau và cùng hoàn thành công việc khai thác. Ngoài ra, với hỗ trợ xử lý bất đồng bộ của Scrapy, nó có thể tối đa hóa việc sử dụng băng thông mạng và cải thiện hiệu quả khai thác và xử lý dữ liệu.
Selenium là gì?
Selenium là một công cụ tự động hóa web mã nguồn mở cho phép bạn điều khiển trình duyệt web theo cách lập trình. Mặc dù nó chủ yếu được sử dụng để kiểm tra các ứng dụng web, Selenium cũng phổ biến trong khai thác web vì nó có thể tương tác với các trang web có nhiều JavaScript, những trang web khó khai thác bằng các phương pháp truyền thống. Quan trọng là Selenium chỉ có thể kiểm tra các ứng dụng web. Chúng ta không thể sử dụng Selenium để kiểm tra các ứng dụng desktop (phần mềm) hoặc ứng dụng di động.
Lõi của Selenium là Selenium WebDriver, cung cấp giao diện lập trình cho phép các nhà phát triển viết mã để kiểm soát hành vi và tương tác của trình duyệt. Công cụ này rất phổ biến trong phát triển và kiểm thử web vì nó hỗ trợ nhiều trình duyệt và có thể chạy trên các hệ điều hành khác nhau. Selenium WebDriver cho phép các nhà phát triển mô phỏng các hành động của người dùng trong trình duyệt, như nhấp nút, điền biểu mẫu và điều hướng trang.
Selenium WebDriver cung cấp nhiều tính năng phong phú, làm cho nó trở thành lựa chọn lý tưởng cho kiểm thử tự động hóa web.
Tính năng chính của Selenium WebDriver
-
Kiểm soát trình duyệt: Selenium WebDriver hỗ trợ nhiều trình duyệt chính, bao gồm Chrome, Firefox, Safari, Edge và Internet Explorer. Nó có thể khởi động và kiểm soát các trình duyệt này, thực hiện các thao tác như mở trang web, nhấp vào các phần tử, nhập văn bản và chụp ảnh màn hình.
-
Tương thích đa nền tảng: Selenium WebDriver có thể chạy trên các hệ điều hành khác nhau, bao gồm Windows, macOS và Linux. Điều này làm cho nó rất hữu ích trong kiểm thử đa nền tảng, cho phép các nhà phát triển đảm bảo ứng dụng của họ hoạt động nhất quán trên nhiều môi trường.
-
Hỗ trợ ngôn ngữ lập trình: Selenium WebDriver hỗ trợ nhiều ngôn ngữ lập trình, bao gồm Java, Python, C#, Ruby và JavaScript. Các nhà phát triển có thể chọn ngôn ngữ mà họ quen thuộc để viết các tập lệnh kiểm tra tự động, từ đó cải thiện hiệu quả phát triển và kiểm tra.
-
Tương tác với các phần tử web: Selenium WebDriver cung cấp API phong phú để tìm kiếm và thao tác các phần tử trang web. Nó hỗ trợ tìm kiếm các phần tử thông qua nhiều phương pháp như ID, tên lớp, tên thẻ, chọn lọc CSS, XPath, v.v. Các nhà phát triển có thể sử dụng các API này để thực hiện các thao tác như nhấp, nhập, chọn và kéo thả.
So sánh Scrapy và Selenium
| Tính năng | Scrapy | Selenium |
|---|---|---|
| Mục đích | Chỉ khai thác web | Khai thác web và kiểm tra web |
| Hỗ trợ ngôn ngữ | Chỉ Python | Java, Python, C#, Ruby, JavaScript, v.v. |
| Tốc độ thực thi | Nhanh | Chậm |
| Tính mở rộng | Cao | Hạn chế |
| Hỗ trợ bất đồng bộ | Có | Không |
| Hiển thị động | Không | Có |
| Tương tác trình duyệt | Không | Có |
| Tiêu thụ tài nguyên bộ nhớ | Thấp | Cao |
Lựa chọn giữa Scrapy và Selenium
-
Chọn Scrapy nếu:
- Mục tiêu của bạn là các trang web tĩnh không có hiển thị động.
- Bạn cần tối ưu hóa tiêu thụ tài nguyên và tốc độ thực thi.
- Bạn cần xử lý dữ liệu rộng rãi và middleware tùy chỉnh.
-
Chọn Selenium nếu:
- Trang web mục tiêu liên quan đến nội dung động và yêu cầu tương tác.
- Hiệu suất thực thi và tiêu thụ tài nguyên không phải là mối quan tâm lớn.
Việc sử dụng Scrapy hay Selenium phụ thuộc vào tình huống cụ thể của ứng dụng, so sánh ưu điểm và nhược điểm của từng công cụ để chọn lựa phù hợp nhất với bạn. Tất nhiên, nếu kỹ năng lập trình của bạn đủ tốt, bạn có thể kết hợp cả Scrapy và Selenium cùng lúc.
Thách thức với Scrapy và Selenium
Dù sử dụng Scrapy hay Selenium, bạn có thể gặp phải cùng một vấn đề: thách thức bot. Các thách thức bot được sử dụng rộng rãi để phân biệt giữa máy tính và con người, ngăn chặn truy cập bot độc hại vào các trang web và bảo vệ dữ liệu khỏi bị khai thác. Các thách thức bot phổ biến bao gồm captcha, reCaptcha, captcha, captcha, Cloudflare Turnstile, captcha, captcha WAF, và nhiều loại khác. Chúng sử dụng các hình ảnh phức tạp và các thách thức JavaScript khó đọc để xác định xem bạn có phải là bot hay không. Một số thách thức thậm chí còn khó vượt qua đối với con người.
Như câu nói: "Mỗi người có một chuyên môn riêng." Sự ra đời của CapSolver đã làm cho vấn đề này trở nên đơn giản hơn. CapSolver sử dụng công nghệ giải CAPTCHA tự động dựa trên AI, có thể giúp bạn giải quyết các thách thức bot trong vài giây. Dù bạn gặp phải loại thách thức hình ảnh hay câu hỏi nào, bạn có thể tự tin giao cho CapSolver. Nếu không thành công, bạn sẽ không bị tính phí.
CapSolver cung cấp một phần mở rộng trình duyệt có thể tự động giải các thách thức CAPTCHA trong quá trình khai thác dữ liệu dựa trên Selenium. Nó cũng cung cấp phương pháp API để giải CAPTCHA và nhận token, cho phép bạn dễ dàng xử lý các thách thức khác nhau trong Scrapy. Tất cả công việc này có thể được hoàn thành chỉ trong vài giây. Tham khảo tài liệu CapSolver để biết thêm thông tin.
Kết luận
Việc lựa chọn giữa Scrapy và Selenium phụ thuộc vào nhu cầu của dự án của bạn. Scrapy lý tưởng cho việc khai thác trang web tĩnh một cách hiệu quả, trong khi Selenium xuất sắc với các trang web động, có nhiều JavaScript. Xem xét các yêu cầu cụ thể, như tốc độ, sử dụng tài nguyên và mức độ tương tác. Đối với việc vượt qua các thách thức như CAPTCHA, các công cụ như CapSolver cung cấp các giải pháp hiệu quả, giúp quá trình khai thác trở nên mượt mà hơn. Cuối cùng, lựa chọn đúng đắn đảm bảo dự án khai thác thành công và hiệu quả.
Câu hỏi thường gặp
1. Scrapy và Selenium có thể được sử dụng cùng nhau trong một dự án không?
Có. Một cách tiếp cận phổ biến là sử dụng Selenium để xử lý việc render JavaScript hoặc các tương tác phức tạp (như quy trình đăng nhập), sau đó chuyển HTML đã render hoặc các URL trích xuất cho Scrapy để khai thác và trích xuất dữ liệu quy mô lớn, tốc độ cao. Mô hình kết hợp này kết hợp sự linh hoạt của Selenium với hiệu suất của Scrapy.
2. Scrapy có phù hợp với các trang web hiện đại có nhiều JavaScript không?
Theo mặc định, Scrapy không thực thi JavaScript, điều này khiến nó không phù hợp với các trang web dựa trên việc render phía client. Tuy nhiên, nó có thể được mở rộng bằng các công cụ như Playwright, Splash hoặc Selenium để xử lý nội dung JavaScript khi cần thiết.
3. Công cụ nào hiệu quả hơn về tài nguyên cho khai thác quy mô lớn?
Scrapy hiệu quả hơn về tài nguyên so với Selenium. Nó sử dụng mạng bất đồng bộ và không cần khởi động trình duyệt, khiến nó phù hợp hơn cho các nhiệm vụ khai thác quy mô lớn, khối lượng lớn. Selenium tiêu tốn nhiều CPU và bộ nhớ hơn vì nó điều khiển một trình duyệt thực tế, điều này giới hạn khả năng mở rộng.
Xem thêm
web scrapingApr 22, 2026
Kiến trúc Trích xuất Dữ liệu Từ Web bằng Rust cho Trích xuất Dữ liệu Có Thể Mở Rộng
Học kiến trúc gỡ mã web Rust có thể mở rộng với reqwest, scraper, gỡ mã bất đồng bộ, gỡ mã trình duyệt không đầu, xoay proxy và xử lý CAPTCHA tuân thủ.

web scrapingFeb 17, 2026
Cách giải CAPTCHA trên Nanobot bằng CapSolver
Tự động hóa việc giải CAPTCHA với Nanobot và CapSolver. Sử dụng Playwright để giải reCAPTCHA và Cloudflare tự động.

